卷积神经网络正式内容笔记 Stanford CS231n 2016
ConvNets
Mathematically
32323(3 channels) Image
filter:553 filter - Convolve the filter with the image: Slide over the image spatially
activation map => 28 * 28 * 1,使用的是$w^T x +b$
then,there is a second filter(553).then there is another activation map.
if we had 6 5x5 filters, we’ll get 6 separate activation maps.
stack up to get 28286 new image,This operation name convolution.
Conv ReLU
Conv -> ReLU -> Pool -> Conv -> ReLU -> Pool -> …-> Pool ->FC -> Output
Common to zero pad the border
- 边界加上一圈border ,0 Pixel
- 一般stride 1
- Conv每层都在减少(减小的太快不好)所以要加padding,加边界
eg:32x32 input convolved repeatedly with 5x5 filters shrinks volumes spatially! (32 -> 28 -> 24 …). Shrinking too fast is not good, doesn’t work well.
Each filter has 553 + 1 = 76 params (+1 for bias)
76*10
Summary
输入长宽深度:$W_1 \times H_1 \times D_1$
4个参数: - K filter的个数 number of filters ,K是2的次幂powers of 2 eg 32,64,128 - F 空间范围 spatial extent filter的空间范围 - S 步长 stride - P 0 padding的总数
Common settings:
K = (powers of 2, e.g. 32, 64, 128, 512) - F = 3, S = 1, P = 1 - F = 5, S = 1, P = 2 - F = 5, S = 2, P = ? (whatever fits) - F = 1, S = 1, P = 0
1x1 的过滤,为了深度
F一般都是odd,奇数~
默认都处理正方形
一般不会去在一层里用多种大小的Filter
计算得到第二层的长宽深度:
因为参数共享,每个过滤器有$F \cdot F \cdot D_1$这么多weights参数,一共有$(F \cdot F \cdot D_1) \cdot K$ + K biases
输出一共有d-th层$ W_2 \times H_2$的卷积结果
把Conv Layer变成Neuron View
An activation map is a 28x28 sheet of neuron outputs: 1. Each is connected to a small region in the input 2. All of them share parameters 因为都是用一个filter变过来的
“5x5 filter” -> “5x5 receptive field for each neuron”
Pool / FC
Pooling Layers
做 downsampling,例如从22422464->11211264
- makes the representations smaller and more manageable
- operates over each activation map independently:
downsampling最常用的是 max pool 用一个2x2的filter,步长为2来求max
Pooling不改变 Depth
Fully Connected Layer (FC)
- Contains neurons that connect to the entire input volume, as in ordinary Neural Networks
可视化很困难
Case Study
- LeCUN 1998
Conv->SubSampleing->Conv->Sub->FC->FC->GC
AlexNet
8 layers
input : 2272273 images
当时GPU Mem不够,所以用了两条分离的线(不考虑)
First Layer: 96 11*11 filters
=> Output: 555596
Parameters: 11113 *96 = 35K
Second Layer: POOL1 : 3x3 at stride 2.No paramter
Pool layer是没有parameters的
Details/Retrospectives: - first use of ReLU - used Norm layers (not common anymore) - heavy data augmentation - dropout 0.5 最后几层FC - batch size 128 - SGD Momentum 0.9 - Learning rate 1e-2, reduced by 10 manually when val accuracy plateaus - L2 weight decay 5e-4 - 7 CNN ensemble: 18.2% -> 15.4%
FC7 feature,再分类之前的最后一次FC
ZFNet
8 layers
[Zeiler and Fergus, 2013]
AlexNet but:
- CONV1: change from (11x11 stride 4) to (7x7 stride 2)
- CONV3,4,5: instead of 384, 384, 256 filters use 512, 1024, 512
ImageNet top 5 error: 15.4% -> 14.8%
VGGNet
19 layers
[Simonyan and Zisserman, 2014]
Only 3x3 CONV stride 1, pad 1 and 2x2 MAX POOL stride 2
19层,11.2% top 5 error in ILSVRC 2013 -> 7.3% top 5 error
主要params在FC层
GoogLeNet
22 layers
[Szegedy et al., 2014]
Inception Module
Inception Layers ,Average
reduce computation & memory
ResNet
152 layers [He et al., 2015]
并不知道何时converge…可能仅仅是训练了两周了,累了….
ILSVRC 2015 winner (3.6% top 5 error)
plain net vs res net
- 2-3 weeks of training on 8 GPU machine
- at runtime: faster than a VGGNet! (even though it has 8x more layers)
Skip connections
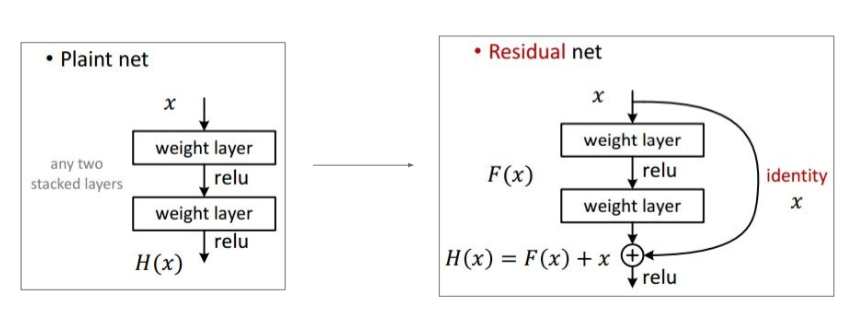
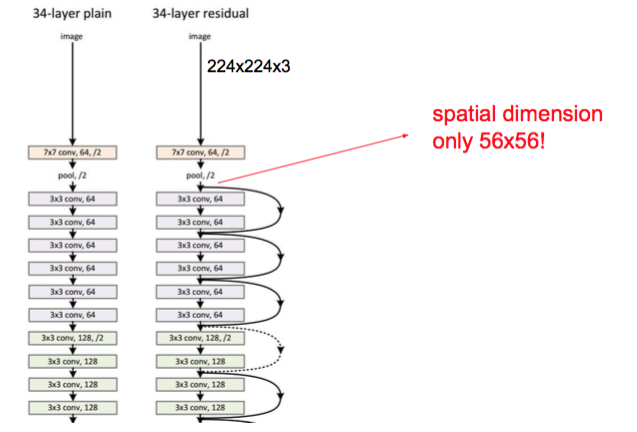
- Batch Normalization after every CONV layer
- Xavier/2 initialization from He et al.
- SGD + Momentum (0.9)
- Learning rate: 0.1, divided by 10 when validation error plateaus
- Mini-batch size 256
- Weight decay of 1e-5
- No dropout used
Alpha Go
policy network
[19x19x48] Input - CONV1: 192 5x5 filters , stride 1, pad 2 => [19x19x192] - CONV2..12: 192 3x3 filters, stride 1, pad 1 => [19x19x192] - CONV: 1 1x1 filter, stride 1, pad 0 => [19x19] => probability map of promising moves