RNN、Image Captioning和LSTM笔记 Stanford CS231n
Recurrent Neural Network
CNN
fixed size image -> fixed size of vector label
-one to one
Image Captioning
- image -> sequence of words
Sentiment Classification
- sequence of words -> sentiment(positive or negative)
Machine Translation
- seq -> seq of words
Video classification on frame level
- before the frame
Process sequentially
fixed inputs vs fixed outputs
- Visual Attention Ba et al
- Draw a RNN for Image Generation Gregor et al
RNN
It has state.through time,feed input vector into RNN.State changing as received input vectors.
usually we can predict a vector at some time steps.
y
^
|
RNN<-self
^
|
xbase on RNN to predict
has states
We can process a sequence of vectors X by applying a recurrence formula at every time step.
$h_t$ is new state,$h_{t-1}$ is old state,$f_W$ is the recurrent function with parameters $W$.
训练出$f_W$里的$W$,使用的时候,use $f_W$ at every single step no matter how long the input or output sequences are.
Vanilla RNN
Simplest.
a single hidden vector $h$.
feed character one at a time into RNN.
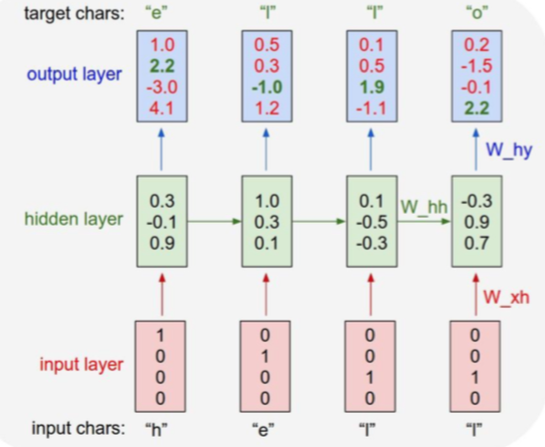
import numpy as np
# data I/O
data = open('input.txt', 'r').read() # should be simple plain text file
chars = list(set(data))
data_size, vocab_size = len(data), len(chars)
print 'data has %d characters, %d unique.' % (data_size, vocab_size)
char_to_ix = { ch:i for i,ch in enumerate(chars) }
ix_to_char = { i:ch for i,ch in enumerate(chars) }
# hyperparameters
hidden_size = 100 # size of hidden layer of neurons
seq_length = 25 # number of steps to unroll the RNN for 必须在内存里都存了,用chunk
learning_rate = 1e-1
# model parameters
Wxh = np.random.randn(hidden_size, vocab_size)*0.01 # input to hidden
Whh = np.random.randn(hidden_size, hidden_size)*0.01 # hidden to hidden
Why = np.random.randn(vocab_size, hidden_size)*0.01 # hidden to output
bh = np.zeros((hidden_size, 1)) # hidden bias
by = np.zeros((vocab_size, 1)) # output bias
def lossFun(inputs, targets, hprev):
"""
inputs,targets are both list of integers.
hprev is Hx1 array of initial hidden state
returns the loss, gradients on model parameters, and last hidden state
"""
xs, hs, ys, ps = {}, {}, {}, {}
hs[-1] = np.copy(hprev)
loss = 0
# forward pass (compute loss)
for t in xrange(len(inputs)):
xs[t] = np.zeros((vocab_size,1)) # encode in 1-of-k representation
xs[t][inputs[t]] = 1
hs[t] = np.tanh(np.dot(Wxh, xs[t]) + np.dot(Whh, hs[t-1]) + bh) # hidden state (RNN的部分)
ys[t] = np.dot(Why, hs[t]) + by # unnormalized log probabilities for next chars
ps[t] = np.exp(ys[t]) / np.sum(np.exp(ys[t])) # probabilities for next chars
loss += -np.log(ps[t][targets[t],0]) # softmax (cross-entropy loss)
# backward pass: compute gradients going backwards
dWxh, dWhh, dWhy = np.zeros_like(Wxh), np.zeros_like(Whh), np.zeros_like(Why)
dbh, dby = np.zeros_like(bh), np.zeros_like(by)
dhnext = np.zeros_like(hs[0])
for t in reversed(xrange(len(inputs))):
dy = np.copy(ps[t])
dy[targets[t]] -= 1 # backprop into y
dWhy += np.dot(dy, hs[t].T)
dby += dy
dh = np.dot(Why.T, dy) + dhnext # backprop into h
dhraw = (1 - hs[t] * hs[t]) * dh # backprop through tanh nonlinearity
dbh += dhraw
dWxh += np.dot(dhraw, xs[t].T)
dWhh += np.dot(dhraw, hs[t-1].T)
dhnext = np.dot(Whh.T, dhraw)
for dparam in [dWxh, dWhh, dWhy, dbh, dby]:
np.clip(dparam, -5, 5, out=dparam) # clip to mitigate exploding gradients
return loss, dWxh, dWhh, dWhy, dbh, dby, hs[len(inputs)-1]
# weight maxtrices
def sample(h, seed_ix, n):
"""
sample a sequence of integers from the model
h is memory state, seed_ix is seed letter for first time step
"""
x = np.zeros((vocab_size, 1))
x[seed_ix] = 1
ixes = []
for t in xrange(n):
h = np.tanh(np.dot(Wxh, x) + np.dot(Whh, h) + bh)
y = np.dot(Why, h) + by
p = np.exp(y) / np.sum(np.exp(y))
ix = np.random.choice(range(vocab_size), p=p.ravel())
x = np.zeros((vocab_size, 1))
x[ix] = 1
ixes.append(ix)
return ixes
n, p = 0, 0
mWxh, mWhh, mWhy = np.zeros_like(Wxh), np.zeros_like(Whh), np.zeros_like(Why)
mbh, mby = np.zeros_like(bh), np.zeros_like(by) # memory variables for Adagrad
smooth_loss = -np.log(1.0/vocab_size)*seq_length # loss at iteration 0
# Main Loop,a batch(25) of data
while True:
# prepare inputs (we're sweeping from left to right in steps seq_length long)
if p+seq_length+1 >= len(data) or n == 0:
hprev = np.zeros((hidden_size,1)) # reset RNN memory
p = 0 # go from start of data
inputs = [char_to_ix[ch] for ch in data[p:p+seq_length]]
targets = [char_to_ix[ch] for ch in data[p+1:p+seq_length+1]]
# sample from the model now and then
if n % 100 == 0:
sample_ix = sample(hprev, inputs[0], 200)
txt = ''.join(ix_to_char[ix] for ix in sample_ix)
print '----\n %s \n----' % (txt, )
# forward seq_length characters through the net and fetch gradient
loss, dWxh, dWhh, dWhy, dbh, dby, hprev = lossFun(inputs, targets, hprev)
smooth_loss = smooth_loss * 0.999 + loss * 0.001
if n % 100 == 0: print 'iter %d, loss: %f' % (n, smooth_loss) # print progress
# perform parameter update with Adagrad
for param, dparam, mem in zip([Wxh, Whh, Why, bh, by],
[dWxh, dWhh, dWhy, dbh, dby],
[mWxh, mWhh, mWhy, mbh, mby]):
mem += dparam * dparam
param += -learning_rate * dparam / np.sqrt(mem + 1e-8) # adagrad update
p += seq_length # move data pointer
n += 1 # iteration counterSearching for interpretable cells
[Visualizing and Understanding Recurrent Networks, Andrej Karpathy, Justin Johnson, Li Fei-Fei]
- quote detection cell
- line length tracking cell
- if statement cell
- quote/comment cell
- code depth cell
Image Captioning Sentence Datasets
Microsoft COCO Tsung-Yi Lin et al. 2014
LSTM
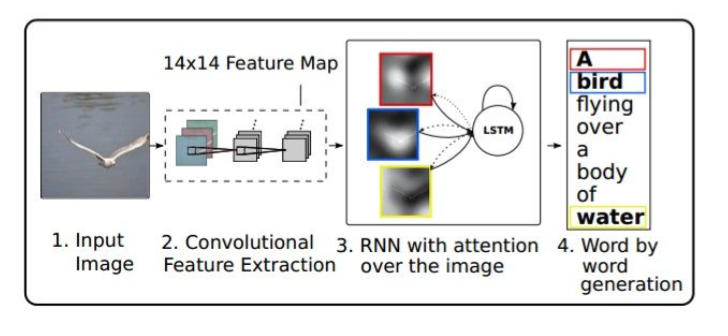
Show Attend and Tell, Xu et al., 2015
得到RNN的结果,用这个结果去看下一步去哪里找
RNN attends spatially to different parts of images while generating each word of the sentence
RNN stack layers,depth and time
LSTM (Long short term memory)
[Hochreiter et al., 1997]

$c_t$ cell state vector
RNN vs LSTM
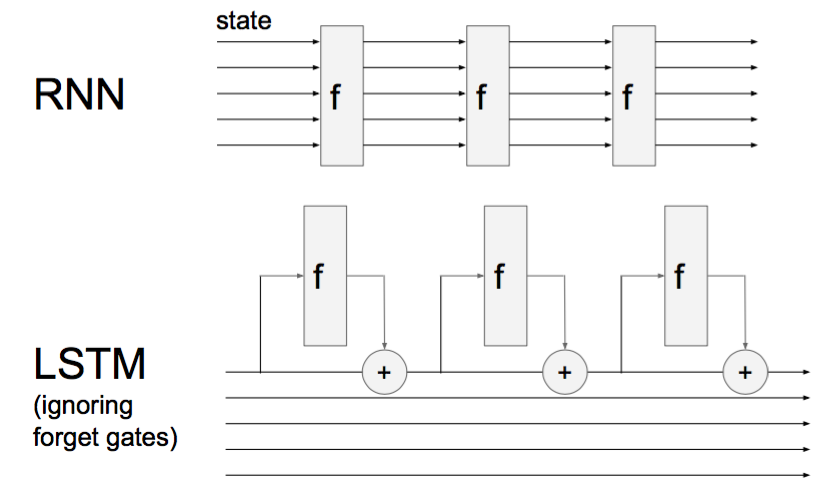
ignoring forget gates
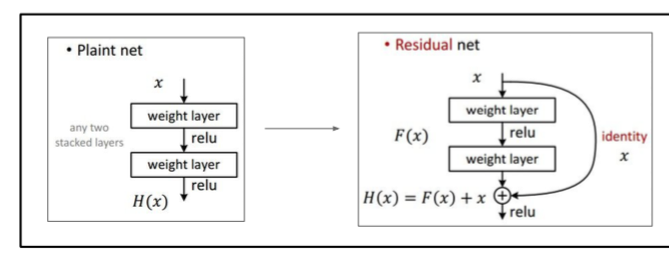
就和“PlainNets” vs. ResNets一样,一个是add,一个是直接传递
RNN 和 LSTM 视觉区别,gradient的变化,RNN很多gradient在传递过来承重逐渐的die了。LSTM is super highway pipeline.
RNN 的不稳定性
因为代码里有个
Whh = np.random.randn(H,H)
...
dss[t] = (hs[t] > 0) * dhs[t];
dhs[t-1] = np.dot(Whh.T,dss[t])导致 if the largest eigenvalue is > 1, gradient will explode (如果太大了,控制住==,大于多少就不增加了)
if the largest eigenvalue is < 1, gradient will vanish
Thesis
[On the difficulty of training Recurrent Neural Networks, Pascanu et al., 2013]
[LSTM: A Search Space Odyssey,Greff et al., 2015]
[An Empirical Exploration of Recurrent Network Architectures,Jozefowicz et al., 2015]
GRU changed LSTM 变量少了
GRU [Learning phrase representations using rnn encoder-decoder for statistical machine translation, Cho et al. 2014]
Raw RNN 工作并不是特别好