ConvNet Image定位、监测、可视化笔记CS231n
Computer Vision task
Localization和Detection的一大区别是,Localization是定位一个,而Detection是多个
Localization:
- Find a fixed number of objects (one or many)
- L2 regression from CNN features to box coordinates
- Much simpler than detection; consider it for your projects!
- Overfeat: Regression + efficient sliding window with FC -> conv conversion
- Deeper networks do better
Object Detection:
- Find a variable number of objects by classifying image regions
- Before CNNs: dense multiscale sliding window (HoG, DPM)
- Avoid dense sliding window with region proposals
- R-CNN: Selective Search + CNN classification / regression
- Fast R-CNN: Swap order of convolutions and region extraction
- Faster R-CNN: Compute region proposals within the network
- Deeper networks do better
Idea #1: Localization as Regression
use box coordinates (4 numbers)
Step 1: Train (or download) a classification model
Image -> Conv & Pooling -> FInal conv feature map -> FC -> class scores -> softmax
Step 2: Attach new fully-connected “regression head” to the network
“Regression head”
Image -> Conv & Pooling -> FInal conv feature map -> FC -> Box coordinates(real number)
Step 3: Train the regression head only with SGD and L2 loss
Step 4: At test time use both heads
如果有C个Classes
Classification head: C numbers
Regression head: C x 4 numbers
Where to attach the regression head?
-
After conv layers: Overfeat, VGG
-
After last FC layer: DeepPose, R-CNN
Aside: Localizing multiple objects
K x 4 numbers (one box per object)
Human Pose Estimation
找到关节 joints
Regress (x, y) for each joint from last fully-connected layer of AlexNet
Toshev and Szegedy, “DeepPose: Human Pose Estimation via Deep Neural Networks”, CVPR 2014
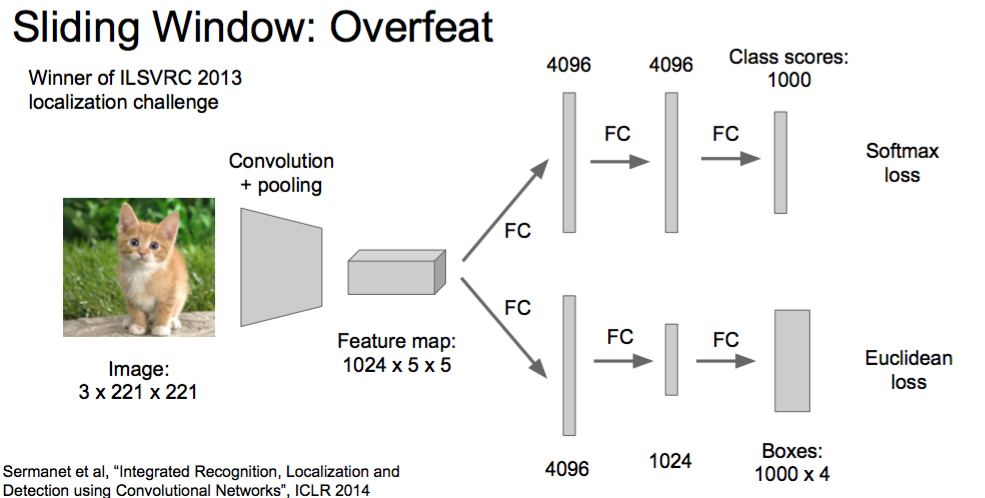
Idea #2: Sliding Window
-
Run classification + regression network at multiple locations on a high-resolution image
-
Convert fully-connected layers into convolutional layers for efficient computation
-
Combine classifier and regressor predictions across all scales for final prediction
L2 distance??????????????
Overfeat
Classification Head & regression head
Sermanet et al, “Integrated Recognition, Localization and Detection using Convolutional Networks”, ICLR 2014
Greedily merge boxes and scores (details in paper)
示意图:
Efficient Sliding Window: Overfeat
Efficient sliding window by converting fully- connected layers into convolutions
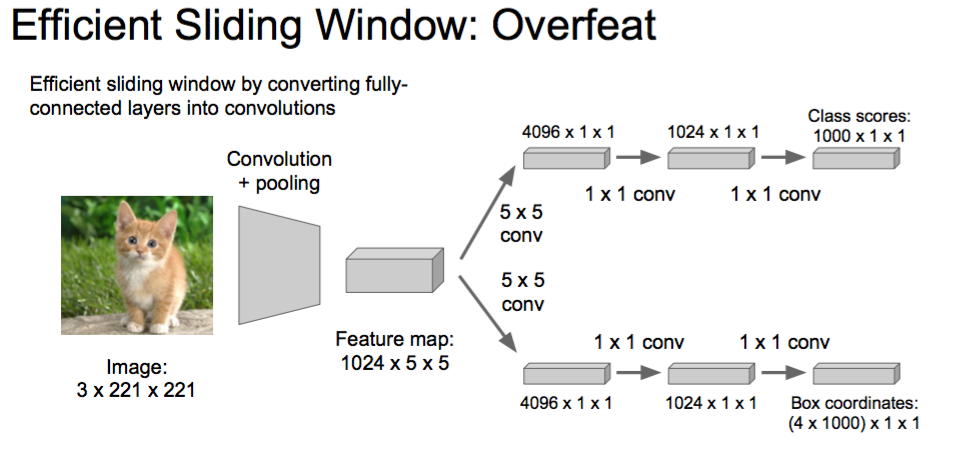
Softmax loss
Euclidean loss
现状
-
AlexNet: Localization method not published
-
Overfeat: Multiscale convolutional regression with box merging
-
VGG: Same as Overfeat(只是deeper了), but fewer scales and locations; simpler method, gains all due to deeper features
-
ResNet: Different localization method (RPN) and much deeper features
Regression 和 Classification are two hammers
Detection
用Classification
如何定window size
Literally try them all
Q:Need to test many positions and scales
A: if your classifier is a fast enough,just do it.
用Linear classifier 然后使用HOG特征,因为快,所以随便大小
Dalal and Triggs, “Histograms of Oriented Gradients for Human Detection”, CVPR 2005 Slide credit: Ross Girshick
Deformable Parts Model (DPM)
Felzenszwalb et al, “Object Detection with Discriminatively Trained Part Based Models”, PAMI 2010
也比较快
Girschick et al,“Deformable Part Models are Convolutional Neural Networks”, CVPR 2015
– Problem: Need to test many positions and scales, and use a computationally demanding classifier (CNN)
Solution: Only look at a tiny subset of possible positions
Region Proposals
- Find “blobby” image regions that are likely to contain objects
- “Class-agnostic” object detector
- Look for “blob-like” regions
Region Proposals: Selective Search
!!!!!!!!!!!!!!
Uijlings et al, “Selective Search for Object Recognition”, IJCV 2013
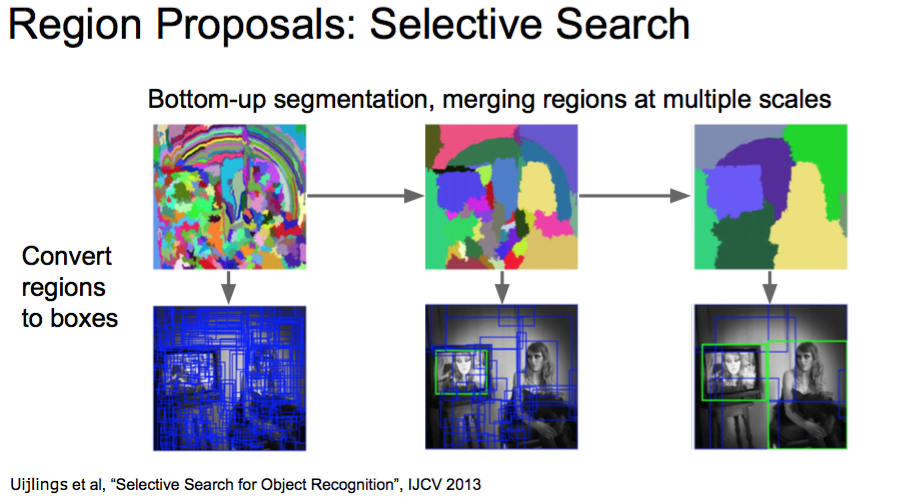
相同的颜色和纹理,然后合并
还有很多其他的方法:
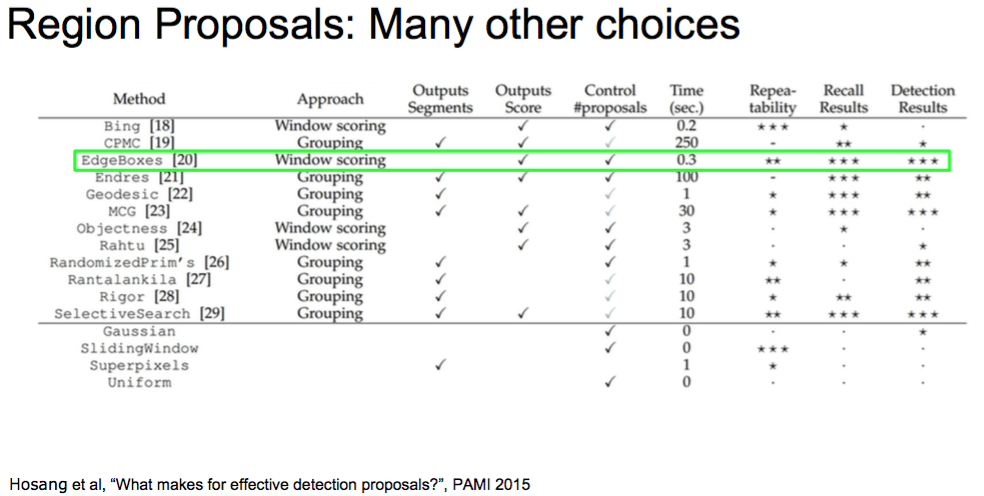
Hosang et al, “What makes for effective detection proposals?”, PAMI 2015
EdgeBoxes
R-CNN
Girschick et al, “Rich feature hierarchies for accurate object detection and semantic segmentation”, CVPR 2014
Region-based
Slide credit: Ross Girschick
R-CNN Training
Step 1: Train (or download) a classification model for ImageNet (AlexNet)
Step 2: Fine-tune model for detection
- Instead of 1000 ImageNet classes, want 20 object classes + background
- Throw away final fully-connected layer, reinitialize from scratch
- Keep training model using positive / negative regions from detection images
Step 3: Extract features
- Extract region proposals for all images
- For each region: warp to CNN input size, run forward through CNN, save pool5 features to disk
- Have a big hard drive: features are ~200GB for PASCAL dataset!
Step 4: Train one binary SVM per class to classify region features
Step 5 (bbox regression): For each class, train a linear regression model to map from cached features to offsets to GT boxes to make up for “slightly wrong” proposals
Correction
PASCAL VOC (2010)
- Number of images ~20k,Mean objects per image 2.4
ImageNet Detection (ILSVRC 2014)
- Number of images ~470k,Mean objects per image 1.1
MS-COCO (2014) 更有意思
- Number of images ~120k,Mean objects per image 7.2
Evaluation
We use a metric called “mean average precision” (mAP)
0~100,100 is good
Compute average precision (AP) separately for each class, then average over classes
A detection is a true positive if it has IoU with a ground-truth box greater than some threshold (usually 0.5) (mAP@0.5)
Combine all detections from all test images to draw a precision / recall curve for each class; AP is area under the curve
TL;DR mAP is a number from 0 to 100; high is good
Wang et al, “Regionlets for Generic Object Detection”, ICCV 2013
R-CNN Problems
-
Slow at test-time: need to run full forward pass of CNN for each region proposal
-
SVMs and regressors are post-hoc: CNN features not updated in response to SVMs and regressors
-
Complex multistage training pipeline
Fast R-CNN
Girschick, “Fast R-CNN”, ICCV 2015
共用一个 ConvNet
Get Region from conv feature map,called ‘Rol pooling layer’
- Share computation of convolutional layers between proposals for an image(解决Slow at test-time)
- Just train the whole system end-to-end all at once!(解决问题2、3)
Region of Interest Pooling
Hi-res conv features: C x H x W with region proposal
Problem: Fully-connected layers expect low-res conv features: C x h x w
Max-pool within each grid cell
R-CNN
- Training Time 84 hours
- Speed up 1x
- Test time per image 47 seconds
Fast R-CNN
- Training Time 9.5 hours
- Speed up 8.8x
- Test time per image 0.32 seconds
Just make the CNN do region proposals too!!!
Faster R-CNN
Insert a Region Proposal Network (RPN) after the last convolutional layer!!!!!!!!!!!!!!!!!!
RPN trained to produce region proposals directly; no need for external region proposals
After RPN, use RoI Pooling and an upstream classifier and bbox regressor just like Fast R-CNN
Ren et al, “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”, NIPS 2015
Slide a small window on the feature map
Build a small network for: - classifying object or not-object, and - regressing bbox locations
Position of the sliding window provides localization information with reference to the image
Box regression provides finer localization information with reference to this sliding window
使用anchor box,先用预先的几个框试一下 - Use N anchor boxes at each location - Anchors are translation invariant: use the same ones at every location - Regression gives offsets from anchor boxes (regressed) anchor shows an object
Since publication: Joint training! One network, four losses
- RPN classification (anchor good / bad)
- RPN regression (anchor -> proposal)
- Fast R-CNN classification (over classes)
- Fast R-CNN regression (proposal -> box)
Faster R-CNN
- Test time per image:0.2 seconds
- (Speedup) 250x
- mAP (VOC 2007) 66.9
spatial transformer network
binary linear interpolation
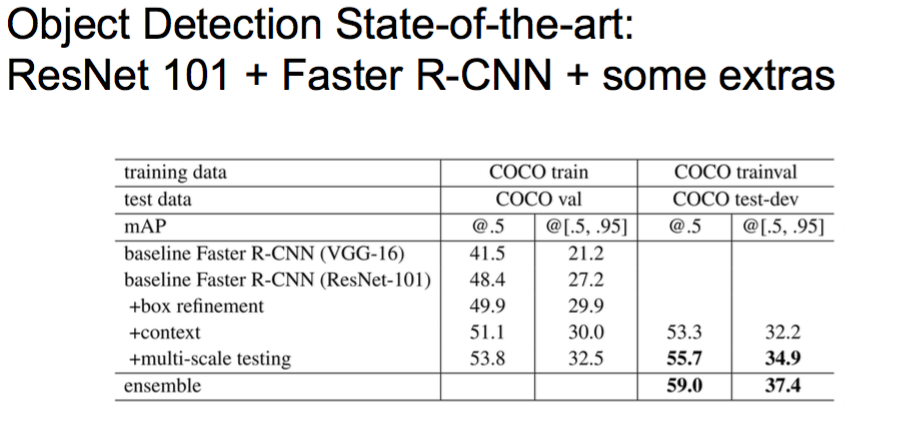
Object Detection State-of-the-art
ResNet 101 + Faster R-CNN + some extras
He et. al, “Deep Residual Learning for Image Recognition”, arXiv 2015
YOLO: You Only Look Once Detection as Regression
Divide image into S x S grid
Within each grid cell predict: B Boxes: 4 coordinates + confidence Class scores: C numbers
Regression from image to 7 x 7 x (5 * B + C) tensor
Direct prediction using a CNN
Redmon et al, “You Only Look Once:Unified, Real-Time Object Detection”, arXiv 2015
Faster than Faster R-CNN, but not as good
Code Links
R-CNN
(Cafffe + MATLAB): https://github.com/rbgirshick/rcnn Probably don’t use this; too slow
Fast R-CNN
(Caffe + MATLAB): https://github.com/rbgirshick/fast-rcnn
Faster R-CNN
(Caffe + MATLAB): https://github.com/ShaoqingRen/faster_rcnn
(Caffe + Python): https://github.com/rbgirshick/py-faster-rcnn
YOLO
http://pjreddie.com/darknet/yolo/
ConvNets
- Visualize patches that maximally activate neurons
- Visualize the weights
- Visualize the representation space (e.g. with t-SNE)
- Occlusion experiments
- Human experiment comparisons
- Deconv approaches (single backward pass)
- Optimization over image approaches (optimization)
t-SNE visualization
Embed high-dimensional points so that locally, pairwise distances are conserved
i.e. similar things end up in similar places. dissimilar things end up wherever
Occlusion experiments
[Zeiler & Fergus 2013]
as a function of the position of the square of zeros in the original image
Deconv approaches
- Feed image into net
- Pick a layer, set the gradient there to be all zero except for one 1 for some neuron of interest
- Backprop to image(“Guided backpropagation:” instead)
[Visualizing and Understanding Convolutional Networks, Zeiler and Fergus 2013]
[Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps, Simonyan et al., 2014]
[Striving for Simplicity: The all convolutional net, Springenberg, Dosovitskiy, et al., 2015]
Backward pass for a ReLU (will be changed in Guided Backprop)
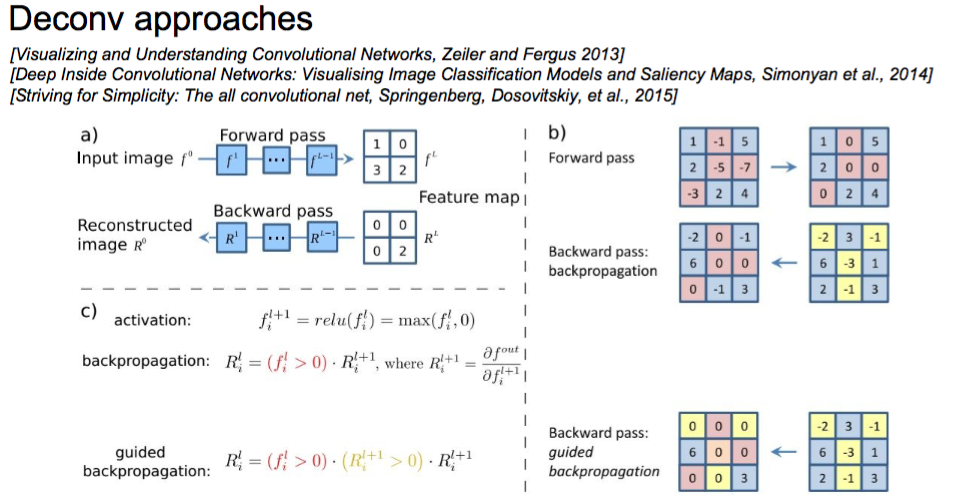
guided bp vs backward pass
Optimization to Image
Q: can we find an image that maximizes some class score? !!!!!!!!!
-
feed in zeros.
-
set the gradient of the scores vector to be [0,0,….1,….,0], then backprop to image
-
do a small “image update”
-
forward the image through the network.
-
go back to 2.
Visualize the Data gradient:
[Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps]
Karen Simonyan, Andrea Vedaldi, Andrew Zisserman, 2014
at each pixel take abs val, and max over channels
Use grabcut for segmentation
- Forward an image
- Set activations in layer of interest to all zero, except for a 1.0 for a neuron of interest
- Backprop to image
- Do an “image update”
Proposed a different form of regularizing the image
Repeat: - Update the image x with gradient from some unit of interest - Blur x a bit - Take any pixel with small norm to zero (to encourage sparsity)
Given a CNN code, is it possible to reconstruct the original image?
Reconstructions from the representation after last last pooling layer(immediately before the first Fully Connected layer)

Reconstructions from intermediate layers

Deep Dream
DeepDream modifies the image in a way that “boosts” all activations, at any layer
对某个neuron刺激最强的那个==
Neural Style
Step 1: Extract content targets (ConvNet activations of all layers for the given content image)
Step 2: Extract style targets (Gram matrices of ConvNet activations of all layers for the given style image)
Step 3: Optimize over image to have:
- The content of the content image (activations match content)
- The style of the style image (Gram matrices of activations match style)
Question: Can we use this to “fool” ConvNets?
[Intriguing properties of neural networks, Szegedy et al., 2013]
[Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images Nguyen, Yosinski, Clune, 2014]
“primary cause of neural networks’ vulnerability to adversarial perturbation is their linear nature“
EXPLAINING AND HARNESSING ADVERSARIAL EXAMPLES [Goodfellow, Shlens & Szegedy, 2014]
In particular, this is not a problem with Deep Learning, and has little to do with ConvNets specifically. Same issue would come up with Neural Nets in any other modalities.
反向加入然后拒绝
Backpropping to the image is powerful. It can be used for:
- Understanding (e.g. visualize optimal stimuli for arbitrary neurons)
- Segmenting objects in the image (kind of)
- Inverting codes and introducing privacy concerns
- Fun (NeuralStyle/DeepDream)
- Confusion and chaos (Adversarial examples)