CNN使用的一些细节
Data augmentation: artificially expand your data
Transfer learning: CNNs without huge data
CNN实战和Caffe
Data Augmentation
如何Transform Image
- 改变像素不改变Label
- Train on transformed data
- VERY widely used
常见:
- Horizontal flips
- Random crops/scales
- Color jitter(eg:Randomly jitter contrast)
- translation
- rotation
- stretching
- shearing,
- lens distortions
- 其他go crazy
Random crops
Training: sample random crops / scales
ResNet 1. Pick random L in range [256, 480] 2. Resize training image, short side = L 3. Sample random 224 x 224 patch
Testing: average a fixed set of crops
- Resize image at 5 scales: {224, 256, 384, 480, 640}
- For each size, use 10 224 x 224 crops: 4 corners + center, + flips
Color jitter
(As seen in [Krizhevsky et al. 2012], ResNet, etc)
- Apply PCA to all [R, G, B] pixels in training set
- Sample a “color offset” along principal component directions
- Add offset to all pixels of a training image
常用
- Training: Add random noise
- Testing: Marginalize over the noise
“You need a lot of a data if you want to train/use CNNs”
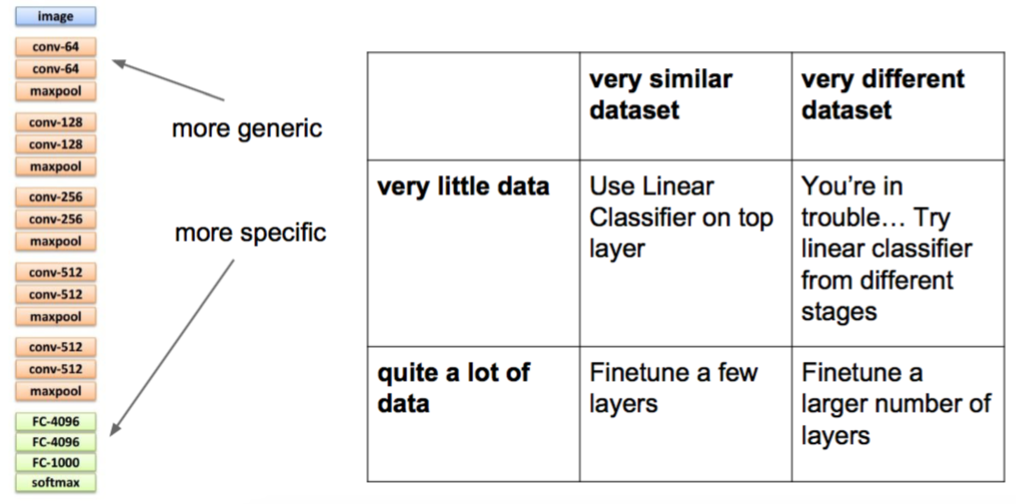
并不是==,Transfer Learning
下载已经训练好的,然后从后面开始替换,重新训练
因为前面的ConvNet,更倾向于一些底层特征
- Train on Imagenet
- small dataset feature extractor(去掉FC+softmax,只训练这两层)
- Medium dataset: Fineturning(从后面再去掉几层ConvNet)
Tip: use only ~1/10th of the original learning rate in finetuning top layer, and ~1/100th on intermediate layers
Thesis
CNN Features off-the-shelf: an Astounding Baseline for Recognition [Razavian et al, 2014]
DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition[Donahue, Jia, et al.,2013]
Transfer Learning 规则
Model Zoo
All About Convolutions
How to stack them
- Suppose we stack two 3x3 conv layers (stride 1)
- Each neuron sees 3x3 region of previous activation map
small fitlers
Suppose input is H x W x C and we use convolutions with C filters
7x7
- 有多少 Weights:$ = C \times (7 \times 7 \times C) = 49 C^2$
- 多少次计算(乘加):= (H x W x C) x (7 x 7 x C) = 49 $H W C^2$
3x3
- 有多少 Weights:$ = 3 \times C \times (3 \times 3 \times C) = 27 C^2$
- 多少次计算(乘加):= 3 x (H x W x C) x (3 x 3 x C) 27 $H W C^2$
相对于7x7,小的3x3:计算量少,非线性多,相对好
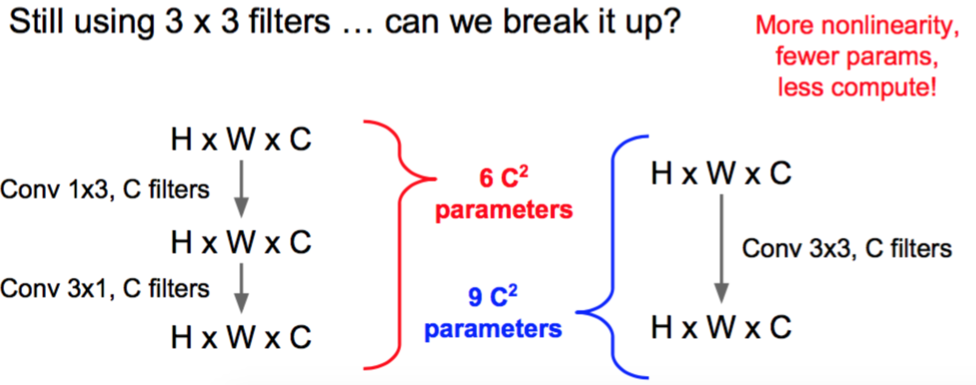
Why stop at 3 x 3 filters? Why not try 1 x 1?
- “bottleneck” 1 x 1 conv to reduce dimension
使用Conv 1x1,C/2 filters
- 3 x 3 conv at reduced dimension
使用Conv 3x3,C/2 filters
- Restore dimension with another 1 x 1 conv
使用 Conv 1x1, C filters
[Seen in Lin et al, “Network in Network”,GoogLeNet, ResNet]
1x1,只需要 $3.25 C^2$ 3x3,需要$9 C^2

或者在1x1中,不使用3x3,使用1x3,3x1
GoogLeNet
Szegedy et al, “Rethinking the Inception Architecture for Computer Vision”
大量使用了1x1、3x3
Recap
- Replace large convolutions (5 x 5, 7 x 7) with stacks of 3 x 3 convolutions
- 1 x 1 “bottleneck” convolutions are very efficient
- Can factor N x N convolutions into 1 x N and N x 1
- All of the above give fewer parameters, less compute, more nonlinearity
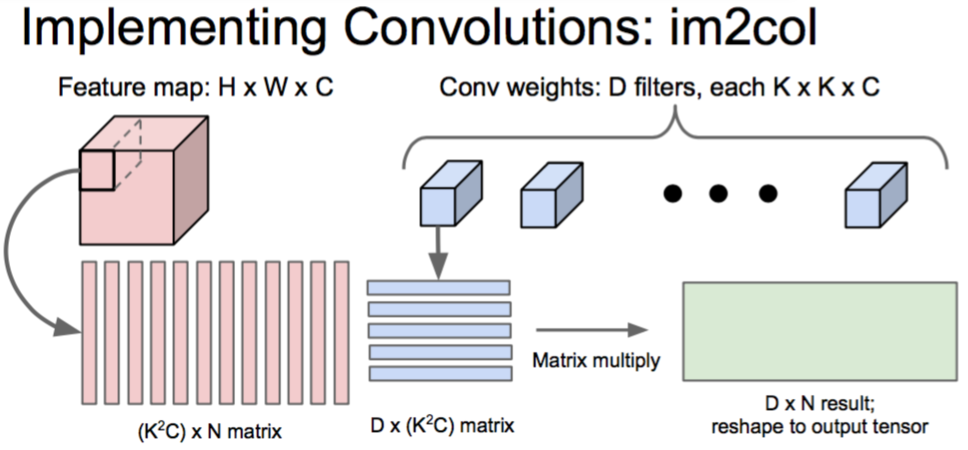
How to compute conv
im2col
将convolution转为matrix multiplication
FFT
Not much speedup for 3x3 filters
Convolution Theorem: The convolution of f and g is equal
Using the Fast Fourier Transform, we can compute the Discrete Fourier transform of an N-dimensional vector in O(N log N) time (also extends to 2D images)
使用FFT来计算Conv
- Compute FFT of weights: F(W)
- Compute FFT of image: F(X)
- Compute elementwise product: F(W) ○ F(X)
- Compute inverse FFT: Y = F-1(F(W) ○ F(X))
Vasilache et al, Fast Convolutional Nets With fbfft: A GPU Performance Evaluation
Fast Algorithms
还没有特别流行,但是很有意思
Lavin and Gray, “Fast Algorithms for Convolutional Neural Networks”, 2015
Implementation Detail
NVIDIA vs AMD
NVIDIA is much more common for deep learning
Introduced new Titan X GPU by bragging about AlexNet benchmarks
CUDA (NVIDIA only) ○ Write C code that runs directly on the GPU ○ Higher-level APIs: cuBLAS, cuFFT, cuDNN, etc
网课 Udacity: Intro to Parallel Programming https://www.udacity.com/course/cs344 ○ For deep learning just use existing libraries
即便用GPU,训练也是很慢
VGG: ~2-3 weeks training with 4 GPUs
ResNet 101: 2-3 weeks with 4 GPUs
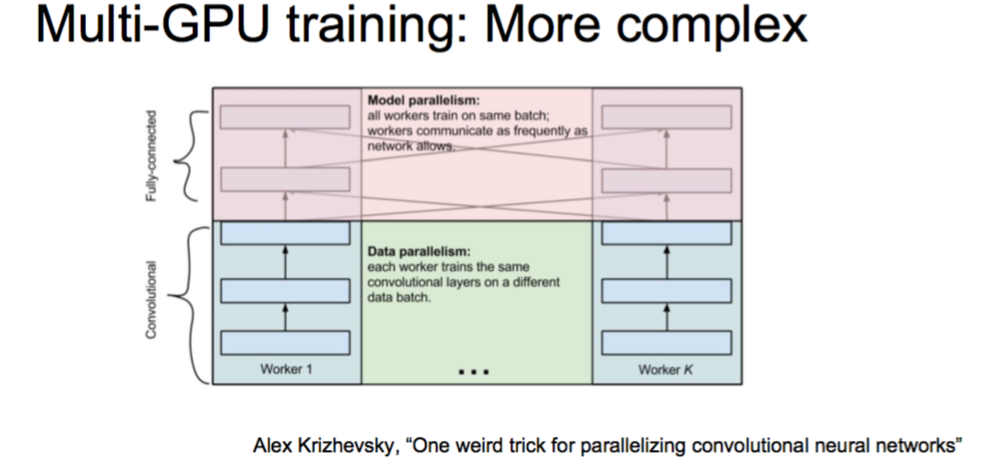
Parallel
Alex Krizhevsky, “One weird trick for parallelizing convolutional neural networks”
[Large Scale Distributed Deep Networks, Jeff Dean et al., 2013]
Google: Synchronous vs Async
Abadi et al, “TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems”
TensorFlow 更多是Distribution
Bottlenecks
1、 GPU - CPU communication is a bottleneck.(尤其是小批量的)
解决方法
CPU data prefetch+augment thread running while GPU performs forward/backward pass
Caffe已经做了
2、CPU - disk bottleneck
Hard disk is slow to read from
解决方法,使用SSD
3、GPU memory bottleneck
Titan X: 12 GB <- currently the max GTX 980 Ti: 6 GB
eg:AlexNet: ~3GB needed with batch size 256
4、Floating Point Precision
-
64 bit “double” precision is default in a lot of programming
-
32 bit “single” precision is typically used for CNNs for performance
Prediction: 16 bit “half” precision will be the new standard
- Already supported in cuDNN
- Nervana(公司名) fp16 kernels are the fastest right now
- Hardware support in next-gen NVIDIA cards (Pascal)
- Not yet supported in torch\caffe
How low can we go?
Gupta et al, 2015:Train with 16-bit fixed point with stochastic rounding
Gupta et al, “Deep Learning with Limited Numerical Precision”, ICML 2015
Courbariaux et al, “Training Deep Neural Networks with Low Precision Multiplications”, ICLR 2015
Train with 10-bit activations, 12-bit parameter updates
!!!!2016年的!!!!!!!!
Courbariaux et al, “BinaryNet: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1”, arXiv 2016
Courbariaux and Bengio, February 9 2016:
● Train with 1-bit activations and weights! ● All activations and weights are +1 or -1 ● Fast multiplication with bitwise XNOR ● (Gradients use higher precision)