Caffe Torch TensorFlow
Written in C++
Has Python and MATLAB bindings
Good for training or finetuning feedforward model
Caffe
不需要写代码有时候==,例如ResNet
Document可能outdated
Four Major Classes:
- Blob : Stores data and derivatives(weights,data,labels) [data diffs],[gpu cpu]
- Layer : input(bottom) blob -> output(top) blob.
- Net : Many Layers. computes gradients via forward/backward
- Solver : Uses gradients to update weights
Protocol Buffers
- Typed Json from google
- Define “message types” in .proto files
- Serialize instances to text files .prototxt
- Compile classes for different languages
Caffe: Training / Finetuning
No need to write code!
- Convert data (run a script)
- Define net (edit prototxt)
- Define solver (edit prototxt)
- Train (with pretrained weights) (run a script)
Convert Data
LMDB:
[path/to/image.jpeg] [label]DataLayer 直接从LMDB读是最方便的
用https://github.com/BVLC/caffe/blob/master/tools/convert_imageset.cpp来创建LMDB
使用h5py去创建HDF5
- ImageDataLayer: Read from image files
- WindowDataLayer: For detection
- HDF5Layer: Read from HDF5 file
- From memory, using Python interface
- All of these are harder to use (except Python)
Define Net
.prototxt can get ugly for big models
ResNet-152 prototxt is 6775 lines long!
一般可以来写Python来生成
直接修改 prototxt
Same name: weights copied
Different name: weights reinitialized
Define Solver
If finetuning, copy existing solver. prototxt file
- Change net to be your net
- Change snapshot_prefix to your output
- Reduce base learning rate (divide by 100)
- Maybe change max_iter and snapshot
例如learning rate,可以改成几个值,然后去用
Train
./build/tools/caffe train \
-gpu 0 \
-model path/to/trainval.prototxt \
-solver path/to/solver.prototxt \
-weights path/to/pretrained_weights.caffemodel-gpu -1 是CPU mode
-gpu all 是多GPU 并行
Model Zoo
AlexNet, VGG, GoogLeNet, ResNet, plus others
Caffe: Python Interface
Not much documentation…
Read the code! Two most important files:
● caffe/python/caffe/_caffe.cpp:
○ Exports Blob, Layer, Net, and Solver classes
● caffe/python/caffe/pycaffe.py
○ Adds extra methods to Net class
Good for:
- Interfacing with numpy
- Extract features: Run net forward
- Compute gradients: Run net backward (DeepDream, etc)
- Define layers in Python with numpy (CPU only)
如果定义layer的话,只能是CPU的
注意下⬆️这里
Caffe Pros / Cons
- (+) Good for feedforward networks
- (+) Good for finetuning existing networks
- (+) Train models without writing any code!
-
(+) Python interface is pretty useful!
- (-) Need to write C++ / CUDA for new GPU layers(在Caffe上写新的Layer很麻烦)
- (-) Not good for recurrent networks = (-) Cumbersome for big networks (GoogLeNet, ResNet)
Torch
- From NYU + IDIAP
- Written in C and Lua
- Used a lot a Facebook, DeepMind
在GPU上运行超简单
必须用Lua来写
Tensors like numpy arrays
require 'cutorch'
require 'cunn'
local dtype = 'torch.CudaTensor'
:type(dtype)https://github.com/torch/torch7/blob/master/doc/tensor.md Document
Torch :: nn
nn module lets you easily build and train neural nets
Build a two-layer ReLU net
Torch : cunn
Import a few new packages
require 'torch'
require 'cutorch'
require 'nn'
require 'cunn'Cast network and criterion
net:type(dtype)
crit:type(dtype)Cast data and labels
local x = torch.randn(N,D):type(dtype)
local y = torch.randn(N).random(C):type(dtype)Torch: optim
update rules: momentum, Adam, etc
Import optim package
requre 'optim'Write a callback function that returns loss and gradients
state variable holds hyperparameters, cached values, etc; pass it to adams
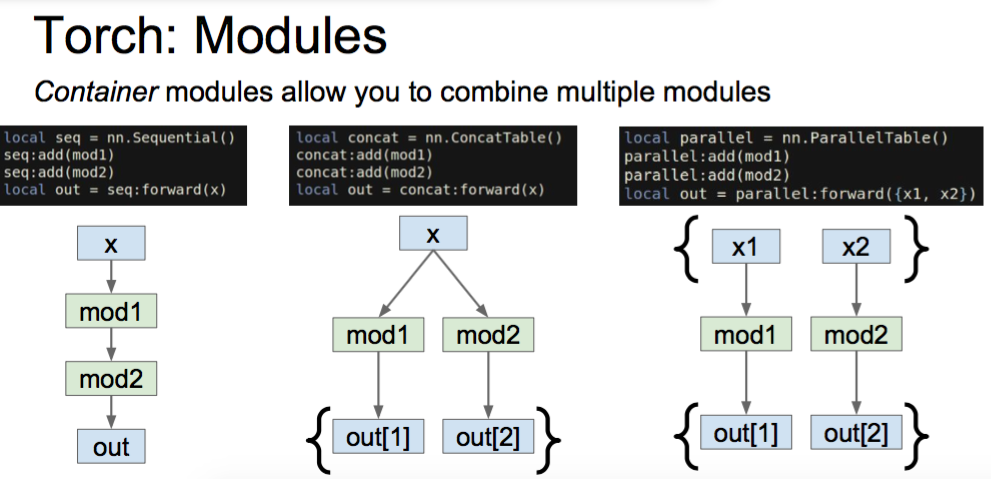
optim.adm(f,weights,state)Torch: Modules
Caffe has Nets and Layers;
Torch just has Modules
- Forward / backward written in Lua using Tensor methods
- Modules are classes written in Lua; easy to read and write
Same code runs on CPU / GPU
Container
- Sequential
- ConcatTable
- ParallelTable
Torch: nngraph
Use nngraph to build modules that combine their inputs in complex ways
Torch: Package Management
loadcaffe: Load pretrained Caffe models: AlexNet, VGG, some others
https://github.com/szagoruyko/loadcaffe
GoogLeNet v1: https://github.com/soumith/inception.torch
GoogLeNet v3: https://github.com/Moodstocks/inception-v3.torch
ResNet: https://github.com/facebook/fb.resnet.torch
Torch: Package Management
like pip : luarocks
Torch: Other useful packages
● torch.cudnn: Bindings for NVIDIA cuDNN kernels
● torch-hdf5: Read and write HDF5 files from Torch
● lua-cjson: Read and write JSON files from Lua,https://luarocks.org/modules/luarocks/lua-cjson
● cltorch, clnn: OpenCL backend for Torch, and port of nn
● torch-autograd: Automatic differentiation; sort of like more powerful nngraph, similar to Theano or TensorFlow
https://github.com/twitter/torch-autograd
● fbcunn: Facebook: FFT conv, multi-GPU (DataParallel, ModelParallel)https://github.com/facebook/fbcunn
Torch: Typical Workflow
Step 1: Preprocess data; usually use a Python script to dump data to HDF5
Step 2: Train a model in Lua / Torch; read from HDF5 datafile, save trained model to disk
Step 3: Use trained model for something, often with an evaluation script
https://github.com/jcjohnson/torch-rnn
Step 1: Preprocess data; usually use a Python script to dump data to HDF5 (https://github.com/jcjohnson/torch-rnn/blob/master/scripts/preprocess.py)
Step 2: Train a model in Lua / Torch; read from HDF5 datafile, save trained model to disk (https://github.com/jcjohnson/torch-rnn/blob/master/train.lua)
Step 3: Use trained model for something, often with an evaluation script (https://github.com/jcjohnson/torch-rnn/blob/master/sample.lua)
Torch: Pros / Cons
- (+) Lots of modular pieces that are easy to combine
- (+) Easy to write your own layer types and run on GPU
- (+) Most of the library code is in Lua, easy to read
-
(+) Lots of pretrained models!
- (-) Not great for RNNs
- (-) Less plug-and-play than Caffe. You usually write your own training code
Theano
Python
http://deeplearning.net/software/theano/
Embracing computation graphs, symbolic computation
High-level wrappers: Keras, Lasagne
Compile a function
在运行的时候,编译新的算法
produces c from x, y, z (generates code)
symbolically!!!!!!!!
Theano computes gradients for us symbolically!
Theano: Computing Gradients
Problem: Shipping weights and gradients to CPU on every iteration to update…
解决方案:Theano: Shared Variables
Define weights as shared variables that persist in the graph between calls; initialize with numpy arrays
w1 = theano.shared(1e-3 * np.random.randn(D,H),name='w1')Function includes an update that updates weights on every call
To train the net, just call function repeatedly!!!!!!!!!!!!!!

还有很多Theano的特性
Lasagne: High Level Wrapper
writes the update rule for you
Keras: High level wrapper
makes common things easy to do
(Also supports TensorFlow backend)
Theano: Pros / Cons
- (+) Python + numpy
- (+) Computational graph is nice abstraction
-
(+) RNNs fit nicely in computational graph
-
(+) High level wrappers (Keras, Lasagne) ease the pain
- (-) Raw Theano is somewhat low-level
- (-) Error messages can be unhelpful
- (-) Large models can have long compile times
- (-) Much “fatter” than Torch; more magic
- (-) Patchy support for pretrained models
编译超级慢
超级复杂
错误超级乱
TensorFlow
Very similar to Theano - all about computation graphs
Easy visualizations (TensorBoard)
Multi-GPU and multi-node training
TensorFlow: Tensorboard
可视化
卧槽!!!
可以做直接画图
而且可以直接画出整个流程图
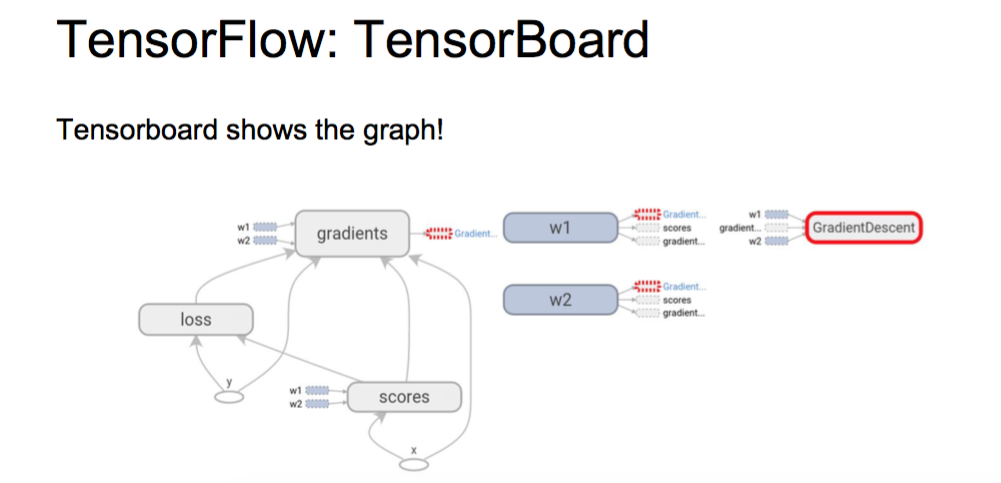
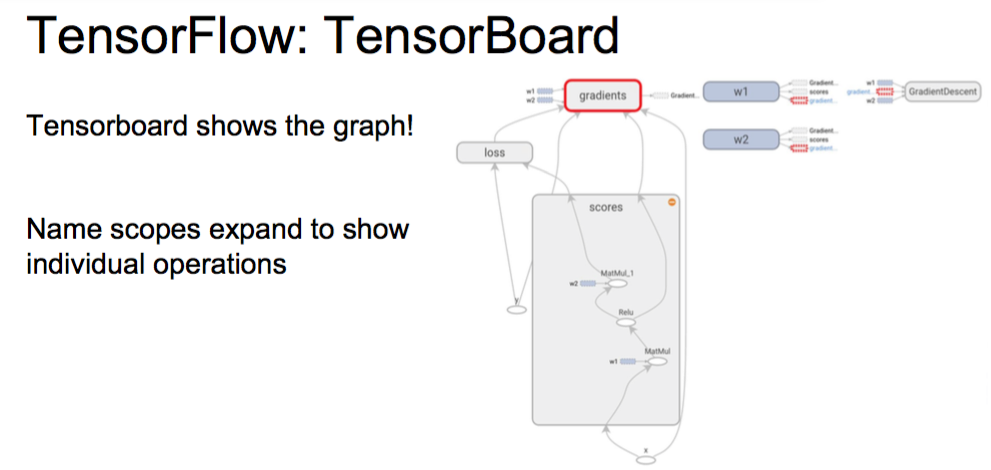
TensorFlow: Pros / Cons
-
(+) Python + numpy
-
(+) Computational graph abstraction, like Theano; great for RNNs
- (+) Much faster compile times than Theano
-
(+) Slightly more convenient than raw Theano?
-
(+) TensorBoard for visualization
- (+) Data AND model parallelism; best of all frameworks
-
(+/-) Distributed models, but not open-source yet
- (-) Slower than other frameworks right now
- (-) Much “fatter” than Torch; more magic
- (-) Not many pretrained models
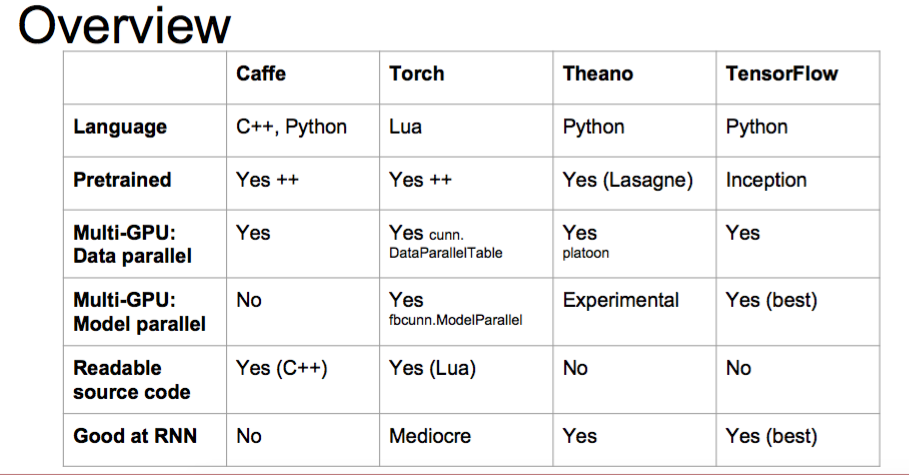
Caffe vs Torch vs Theano vs TensorFlow
Segmentation? (Classify every pixel)
- Need pretrained model (Caffe, Torch, Lasagna)
- Need funny loss function
- If loss function exists in Caffe: Use Caffe
- If you want to write your own loss: Use Torch
Object Detection?
-> Use Caffe + Python or Torch
Language modeling with new RNN structure?
-> Use Theano or TensorFlow
Implement BatchNorm?
-> Implement efficient backward pass? Use Torch
Recommendation
-
Feature extraction / finetuning existing models: Use Caffe
-
Complex uses of pretrained models: Use Lasagne or Torch
-
Write your own layers: Use Torch
-
Crazy RNNs: Use Theano or Tensorflow
-
Huge model, need model parallelism: Use TensorFlow
neon™
The Fastest Deep Learning Framework
neon™ is open source and can be deployed on CPUs, GPUs or custom Nervana hardware. It supports all the commonly used models including convnets, MLPs, RNNs, LSTMs and autoencoder