分割、Attention Model与空间变化 笔记
Szegedy et al, Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, arXiv 2016
GoogLeNet-v4
Top 5,error 3.08%
Segmentation
-
Semantic Segmentation(不知道有几个,只是对每个像素label了)
-
Instance Segmentation(SDS,对每个个体都要区分,不同的人也要分)
Semantic Segmentation
Figure credit: Shotton et al, “TextonBoost for Image Understanding: Multi-Class Object Recognition and Segmentation by Jointly Modeling Texture, Layout, and Context”, IJCV 2007
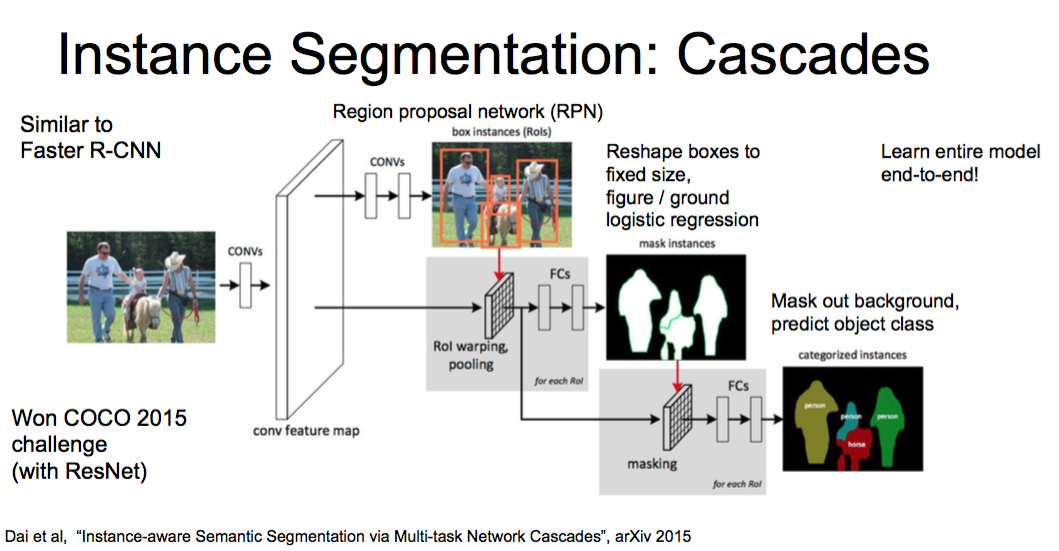
Instance Segmentation
Figure credit: Dai et al, “Instance-aware Semantic Segmentation via Multi-task Network Cascades”, arXiv 2015
Semantic Segmentation
输出图像因为Pooling,会比之前的小
image pyramid
Resize to multiple different sizes
each scales -> run one cnn per scale -> up scale ouputs and concatenate
法2
RGB三个通道
Apply CNN once
More iterations improve results
Pinheiro and Collobert, “Recurrent Convolutional Neural Networks for Scene Labeling”, ICML 2014
Long, Shelhamer, and Darrell, “Fully Convolutional Networks for Semantic Segmentation”, CVPR 2015
Learnable upsampling!
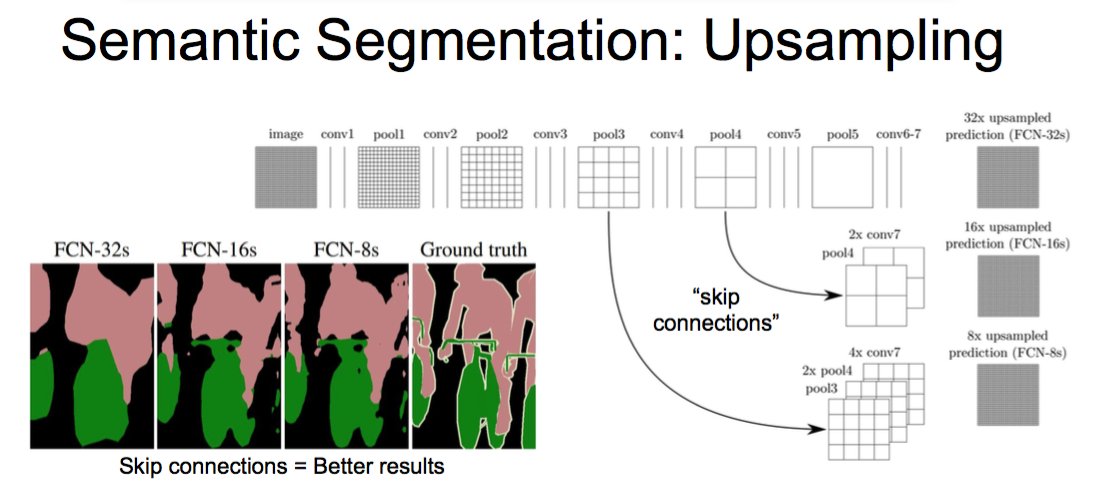
skip connections
Better results
从pool3或者pool4跳到最后
Deconvolution
!!!Input gives weight for filter
convolution的时候,stride1,deconvolution的时候stride2
重叠的地方,相加
Same as backward pass for normal convolution!
“inverse of convolution”
名字:
convolution transpose,backward strided convolution,1/2 strided convolution,upconvolution
名字的争论的论文。。。。
- Im et al, “Generating images with recurrent adversarial networks”, arXiv 2016
- Radford et al, “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks”, ICLR 2016
Instance Segmentation
Input->Region Proposal (Segment Proposal) -> External Segment proposal
然后两条路,一条Feature Extraction另一条 R-CNN
->Region CLassification
->Refinement
判断foreground还是background
Hariharan et al, “Hypercolumns for Object Segmentation and Fine-grained Localization”, CVPR 2015
Google Instance Segmentation COCO2015获胜
Dai et al, “Instance-aware Semantic Segmentation via Multi-task Network Cascades”, arXiv 2015
Region proposal network (RPN)
然后使用Rol warping pooling

Attention Models
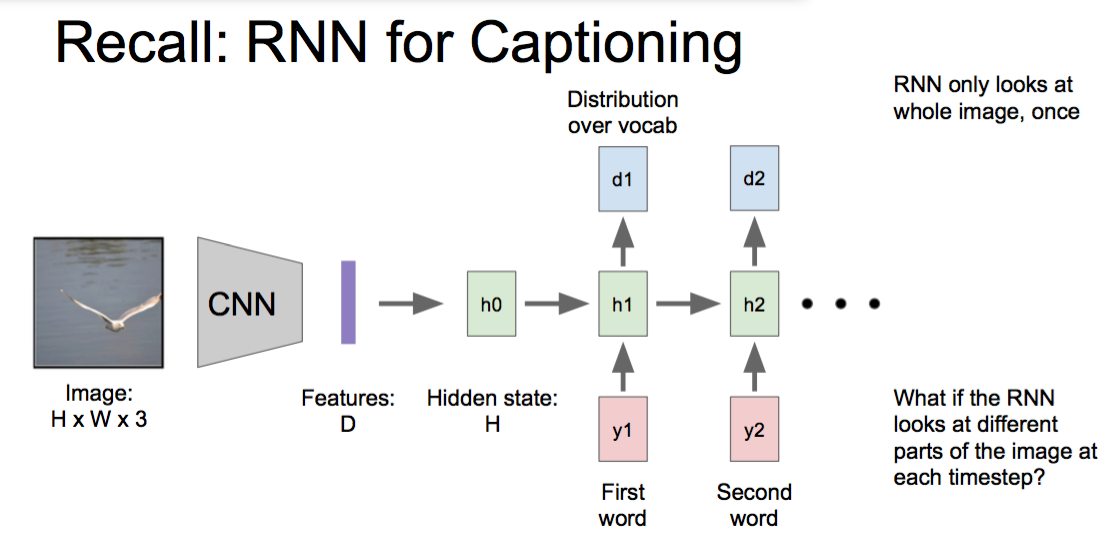
Attention Models
每次处理并不是全部处理所有的Input,每次处理只处理最Attention的那部分
最近很火
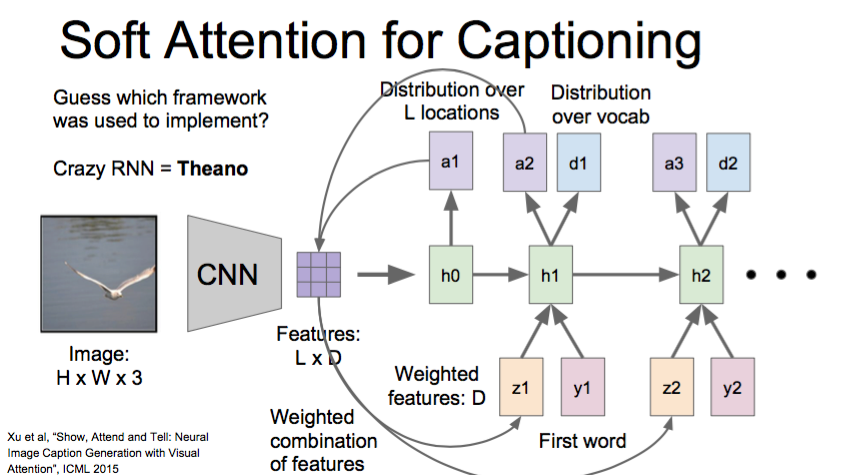
Xu et al, “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention”, ICML 2015
R-CNN
Soft Attention
reinforcement learning
但是不知道在自由图片上的效果
Soft Attention for Translation
Sequence -> Sequence
Video captioning,attention over input frames:
- Yao et al, “Describing Videos by Exploiting Temporal Structure”, ICCV 2015
Image, question to answer,attention over image:
-
Xu and Saenko, “Ask, Attend and Answer: Exploring Question-Guided Spatial Attention for Visual Question Answering”, arXiv 2015
-
Zhu et al, “Visual7W: Grounded Question Answering in Images”, arXiv 2015
RNN handwriting
Graves, “Generating Sequences with Recurrent Neural Networks”, arXiv 2013
Demo http://www.cs.toronto.edu/~graves/handwriting.html
Spatial Transformer Networks
Jaderberg et al, “Spatial Transformer Networks”, NIPS 2015
Soft attention:
- Easy to implement: produce distribution over input locations, reweight features and feed as input
- Attend to arbitrary input locations using spatial transformer networks
Hard attention:
- Attend to a single input location
- Can’t use gradient descent!
- Need reinforcement learning
Selectively paying attention to different parts of the image