视频处理笔记
Feature-based approaches to Activity Recognition
Dense trajectories and motion boundary descriptors for action recognition
Wang et al., 2013
Action Recognition with Improved Trajectories
Wang and Schmid, 2013
用来track视频中什么有变化
[T. Brox and J. Malik, “Large displacement optical flow: Descriptor matching in variational motion estimation,” 2011]

Q: What if the input is now a small chunk of video? E.g. [227x227x3x15] ?
A: Extend the convolutional filters in time, perform spatio-temporal convolutions!E.g. can have 11x11xT filters, where T = 2..15.
filter不仅在空间上移动,还在时间上移动
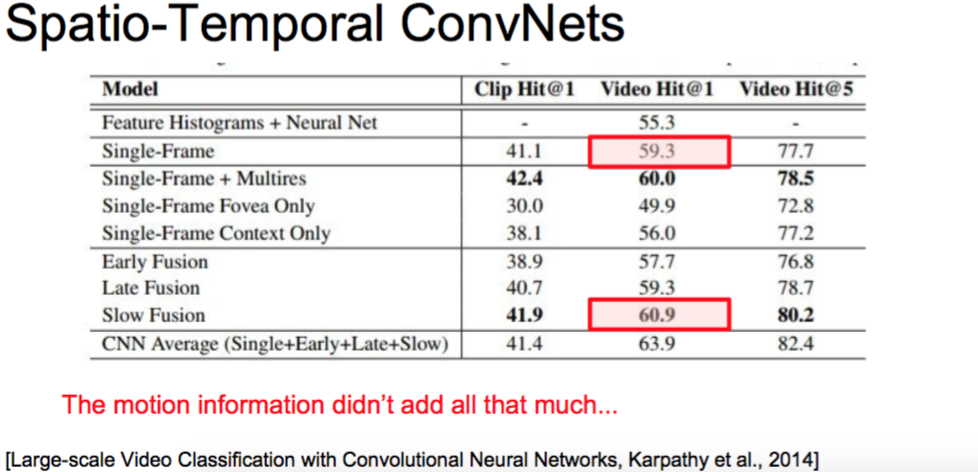
Spatio-Temporal ConvNets
Before AlexNets [3D Convolutional Neural Networks for Human Action Recognition, Ji et al., 2010]
[Sequential Deep Learning for Human Action Recognition, Baccouche et al., 2011]
After
[Large-scale Video Classification with Convolutional Neural Networks, Karpathy et al., 2014]
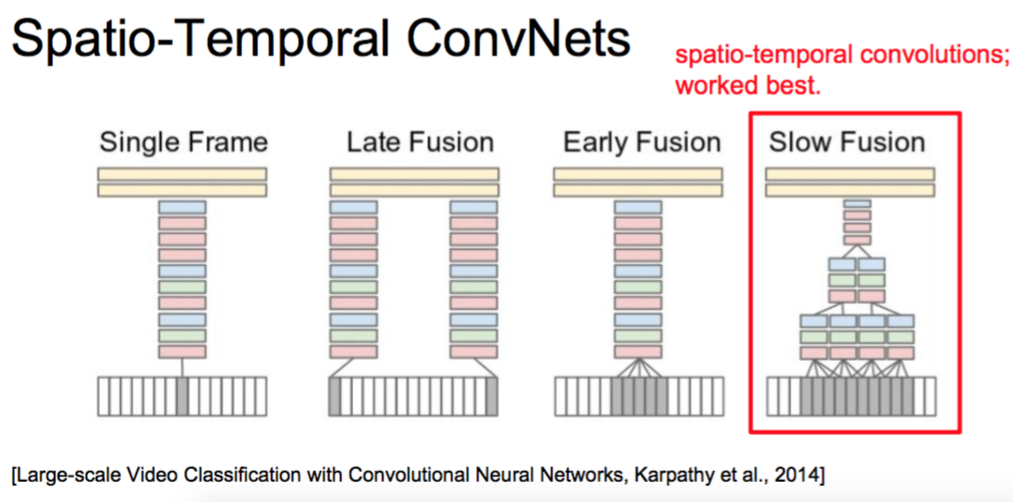
Single Frame ->非常好的一种,比较推荐先尝试这个
C3D architechure
in time & VGG & work well
[Learning Spatiotemporal Features with 3D Convolutional Networks, Tran et al. 2015]
2D convolution
Simonyan 是VGG的提出人
[Two-Stream Convolutional Networks for Action Recognition in Videos, Simonyan and Zisserman 2014]
Two-stream version works much better than either alone.
Longer Term Events
使用LSTM
[Long-term Recurrent Convolutional Networks for Visual Recognition and Description, Donahue et al., 2015]
[Beyond Short Snippets: Deep Networks for Video Classification, Ng et al., 2015]
奇葩!!!
(This paper was way ahead of its time. Cited 65 times.)
Sequential Deep Learning for Human Action Recognition, Baccouche et al., 2011
三种构架
- Model temporal motion locally (3D CONV)
- Model temporal motion globally (LSTM / RNN)
- Fusions of both approaches at the same
idea:快进快退
Long-time Spatio-Temporal ConvNets
[Delving Deeper into Convolutional Networks for Learning Video Representations, Ballas et al., 2016]
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! 很重要,这个应该能用
GRU是一个LSTM的简化算法
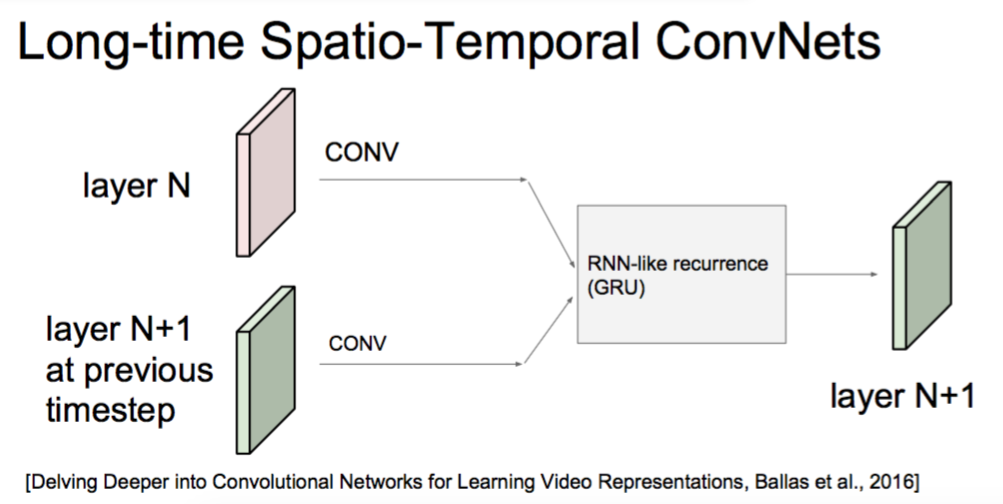
Infinite (in theory) temporal extent
(neurons that are function of all video frames in the past)
注意
在做视频的时候,事先考虑Spatial Temporal Video ConvNet
确定需要local motion(3D Conv)还是global motion(LSTM)
Try out using Optical Flow in a second stream
Try out GRU-RCN! (imo best model)
Unsupervised
Clustering, dimensionality reduction, feature learning, generative models, etc
Autoencoders
- Vanilla Traditional: feature learning
- Variational: generate samples
● Generative Adversarial Networks: Generate samples
Encoder
输入Data,经过Encoder,然后去找Features
Feature一般比Data小,所以可以用于降维
然后通过Decoder,然后通过Features重建Input Data
Decoder和Encoder 的Weight是共享的
-
After training, throw away decoder!
-
Use encoder to initialize a supervised model
三层NN,不过输入输出一样,因为需要中间的Features,要用到其他地方
PCA可以解决一部分,更多是Reconstruction
Variational Autoencoder: Encoder
Kingma and Welling, “Auto-Encoding Variational Bayes”, ICLR 2014
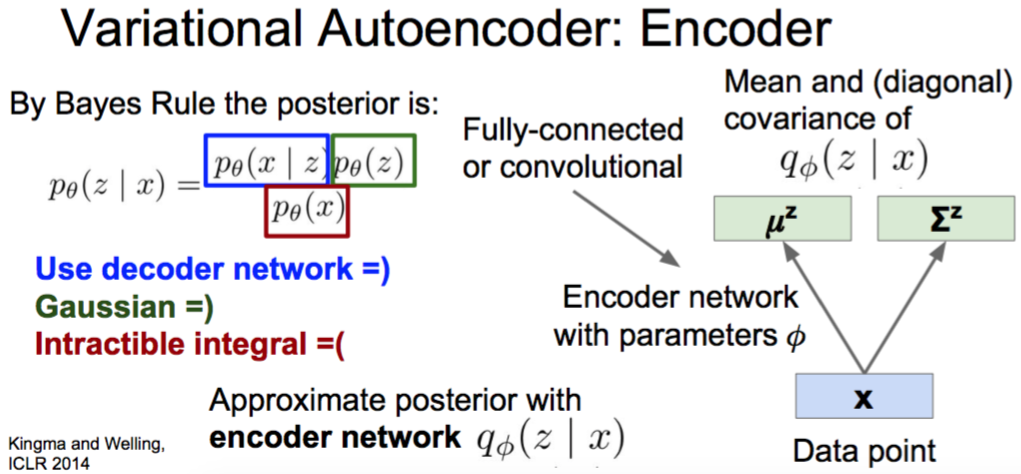
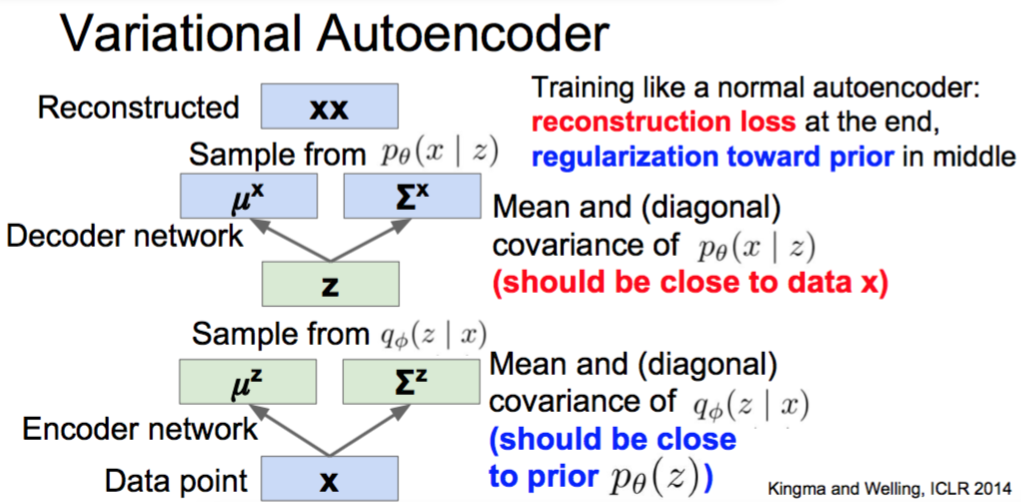
完全没听懂==

Goodfellow et al, “Generative Adversarial Nets”, NIPS 2014
Generative Adversarial Nets: Multiscale
Generator is an upsampling network with fractionally-strided convolutions
Discriminator is a convolutional network
Radford et al, “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks”, ICLR 2016
!!!!!!!!!!!! 超牛逼
Radford et al,ICLR 2016
Generative Adversarial Nets: Vector Math


Put everything together
Dosovitskiy and Brox, “Generating Images with Perceptual Similarity Metrics based on Deep Networks”,arXiv 2016